Il 1° luglio 2020 si è svolto un meetup per approfondire alcuni aspetti del risk management e come l’intelligenza artificiale può essere utilizzata per contribuire a prendere le decisioni di investimento, sul sito di MeetUp.com si possono leggere la descrizione dell’evento e l’elenco dei partecipanti.
Copertina del MeetUp sull’intelligenza artificiale per la gestione del rischio.
A parlare di Machine Learning e delle sue applicazioni sono Fabrizio Monge, data analyst e consulente finanziario, con una brillante esperienza nei modelli di risk management con profilo LinkedIn, e Gabriele Turissini, private banker con profilo LinkedIn, che fornisce una lettura originale e approfondita del tema, moderatore Daniele Bernardi con profilo LinkedIn.
La registrazione video si può rivedere su Facebook.
L’utilizzo del machine learning nella gestione del rischio
del portafoglio finanziario ha molteplici applicazioni.
Se infatti la natura di complex system del mercato rende
molto difficile e pericoloso tentare di fare previsioni in senso stretto, è altrettanto
vero che i mercati attraversano delle fasi caratterizzate da patterns non
lineari ricorrenti nelle fasi di crisi.
Proprio in questo caso, almeno per l’esperienza di Monge,
gli strumenti di ML costituiscono una valigetta degli attrezzi estremamente
utile, sia in fase esplorativa che in ambito predittivo probabilistico.
Un esempio è l’analisi delle metriche strutturali del
network delle azioni che compongono un indice, su cui Monge sta lavorando con
Enrico Fenoaltea dell’Università di Fisica di Copenaghen e Matteo Boidi del
Politecnico di Torino.
L’analisi delle serie storiche delle metriche appare a prima vista correlata con la volatilità dell’indice, ma solo attraverso l’elaborazione con sistemi di bagging and boosting di decision trees essi sono riusciti a evidenziare dei patterns che consentono una diagnosi precoce delle fasi di crisi del mercato finanziario.
Durante il webinar Monge ha presentato il libro “Algoritmi per l’Intelligenza Artificiale” nella bibliografia che consiglia, unico libro in lingua italiana in mezzi ad altri libri in lingua inglese.
Libri consigliati durante il MeetUp sull’intelligenza artificiale per la gestione del rischio.
LinkedIn, il noto business social network gestito da Microsoft, è molto importante per creare contatti professionali, essere aggiornato, trovare posizioni di lavoro, contattare clienti e fornitori, e tanto altro.
Per ricevere il flusso di notizie create dai nostri contatti, bisogna entrare nel proprio account e cliccare in alto sull’icona Home, oppure cliccare sull’indirizzo https://www.linkedin.com/feed/,
Esiste anche una importante fonte di informazioni: il servizio Notizie con home page illustrata nell’immagine precedente, in cui 65 giornalisti da tutto il mondo selezionano i fatti di attualità utili per mantenersi informato nella vita professionale. Nel link indicato sono riportati i nomi dei giornalisti italiani ed esteri, da seguire per ricevere ulteriori notizie e per capire come operano.
Le notizie scelte vengono pubblicate nella pagina Daily Rundown raggiungibile solo dopo essere entrati con l’account.
Si tratta di una importante risorsa per due motivi:
non si ha tempo di leggere tutto, una selezione curata da esperti può aiutare;
se abbiamo scritto un post o un articolo in LinkedIn, potrebbe venire rilanciato in questa raccolta, con un grosso vantaggio nella diffusione del nostro profilo personale.
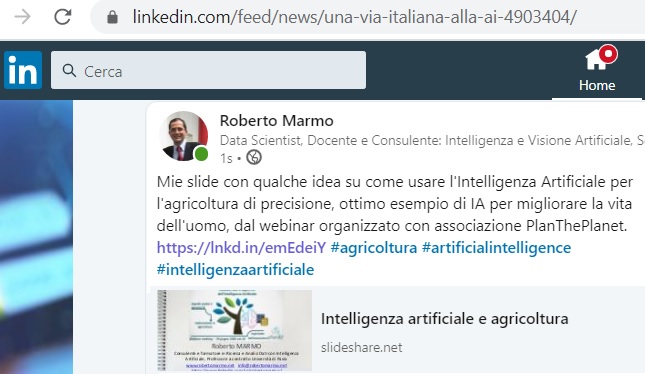
Nella sezione con titolo “Una via italiana alla AI” si può leggere un esempio di rilancio del post sulla pubblicazione in Slideshare.net di slide sull’intelligenza artificiale e agricoltura scritte dall’autore del libro Roberto Marmo, come mostrato nell’immagine seguente. L’autore ha pubblicato il testo come post nel suo profilo personale, è stato notato dalla redazione, lo hanno ritenuto degno di essere ripubblicato, probabilmente anche grazie alle interazioni ricevute da altre persone.
LinkedIn Notizie rilancia un post scritto nel profilo personale.
Per trovare gli articoli più recenti si può visitare la pagina Daily Rundown, per cercare negli altri articoli si può usare Google con questa combinazione: site:https://www.linkedin.com/feed/news PAROLE CHIAVE, in cui sostituire PAROLE CHIAVE con le parole di interesse. Alcuni esempi:
site:https://www.linkedin.com/feed/news deep learning
in tal modo, si arriva a una pagina web piuttosto lunga con
vari articoli, per trovare quello di interesse si può usare la ricerca offerta
dal browser, in cui ripetere le parole chiave scelte per arrivare direttamente
al punto desiderato.
Vuoi conoscere l’Intelligenza Artificiale e sapere come applicarla nella tua azienda per aumentare i ricavi e ridurre i costi?
CFM Italia organizza un webinar gratuito con Roberto Marmo giovedì 2 luglio dalle ore 15.00 alle ore 16 su Zoom. Il biglietto gratuito si prenota su EventBrite.
Parleremo di Intelligenza Artificiale applicata alle PMI e MPMI, approfondiremo l’opportunità dei voucher messi a disposizione dalla Regione Lombardia per la formazione ai dipendenti e titolari di aziende o liberi professionisti lombardi.
Infatti, il webinar è un’occasione per saperne di più sui corsio di formazione con didattica organizzata da CFM e Roberto Marmo nella programmazione in Python e creazione di applicazioni per sfruttare l’intelligenza artificiale.
Sono corsi di formazione personalizzati, appositamente pensati per le MPMI e i liberi professionisti, che grazie a questi voucher sono a costo zero.
Per conoscere l’importanza di queste tematiche leggi anche l’intervista pubblicata su LinkedIn Pulse o sul sito di CFM.
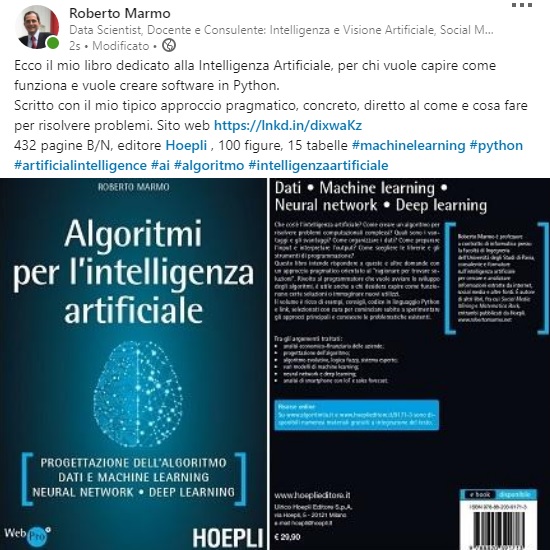
Per promuovere il libro “Algoritmi per l’Intelligenza Artificiale” è stato creato un post nel profilo LinkedIn dell’autore Roberto Marmo, illustrato in questa immagine e raggiungibile a questo link.
Post su LinkedIn di presentazione del libro “Algoritmi per l’Intelligenza Artificiale”.
In 10 giorni ha raggiunto 7.100 visualizzazioni nel flusso di notizie degli utenti, nei primi 5 giorni erano 5.000, 126 reazioni e 17 commenti. I numeri sono superiori ai 2.000 contatti del profilo, perché molte persone hanno condiviso il post.
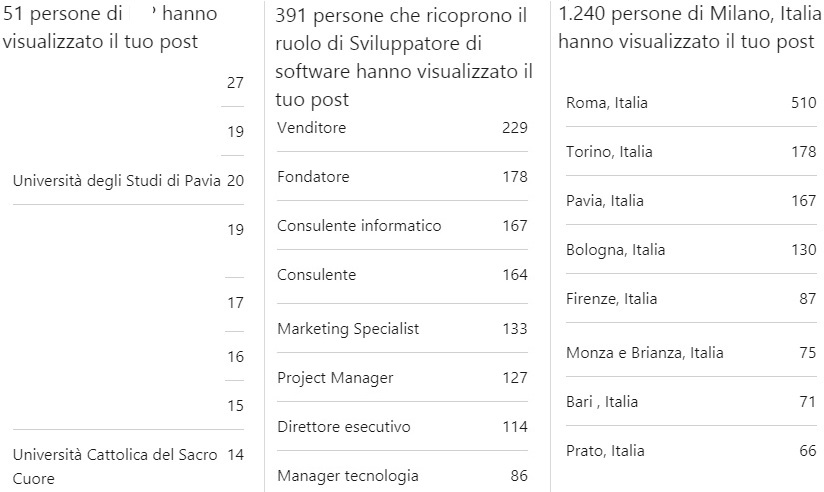
L’immagine seguente mostra le statistiche sulla diffusione del post, per evitare questioni di riservatezza sono oscurati i nomi delle aziende, si tratta di realtà molto grandi con dimensione internazionale.
LinkedIn Analytics del post nell’immagine precedente.
I dati mostrati derivano dai contatti esistenti nel profilo LinkedIn dell’autore in area Milano con interessi in intelligenza artificiale e marketing. Il post è stato condiviso e ha raggiunto persone diverse dai contatti, questi dati suggeriscono l’area geografica e l’attività delle persone interessate all’intelligenza artificiale.
Commodore 64, a sinistra la prima versione, a destra l’aggiornamento.
Il Commodore 64, abbreviato C64, è un home computer della Commodore Business Machines Inc. commercializzato dal 1982 al 1994. Fu immesso sul mercato due anni dopo il Commodore VIC-20. La macchina è stata la più venduta nella storia dell’informatica, con circa 22 milioni di unità prodotte e vendute. Dotato di 64 kB di RAM, microprocessore MOS 6510, linguaggio di programmazione Basic.
Grazie alla sua ampia diffusione e all’interesse per l’intelligenza artificiale mostrato negli anni ’80 nell’ambito dei sistemi esperti e logica fuzzy, anche con il C64 sono stati svolte varie sperimentazioni.
La pagina dedicata all’Artificial Intelligence nella C64 Wiki riporta la creazione di Eliza, chatterbot che fa la parodia di un terapeuta Rogersiano, e di 226 righe in Basic per creare una neural network con decine di neuroni e migliaia di connessioni. Nel sito di John Walker si può trovare la descrizione della rete e il codice usato.
I libri seguenti spiegano come realizzare alcune applicazioni, dai loro indici si possono notare gli approcci considerati.
Introduction 7 Artificial Intelligence 9 Just Following Orders 13 Understanding Natural Language 29 Making Reply 47 Expert Systems 65 Making Your Expert System Learn for Itself 79 Fuzzy Matching 93 Recognising Shapes 105 An Intelligent Teacher 117 Putting It All Together 125
Introduction to Artificial Intelligence 1
Intelligent Games 21
Behaviors and Bootstraps 39
Natural Language Processing 51
Heuristic 83
Pattern Recognition 99
Other Areass in Artificial Intelligence 116
Glossary 125
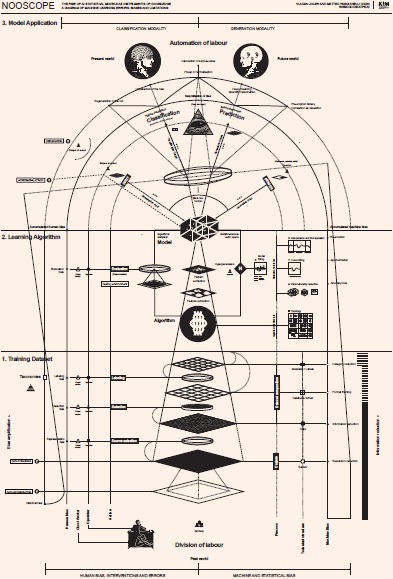
Su Nooscope.ai si può leggere in dettaglio questo diagramma, in cui viene mostrato un diagramma che mostra come funziona il machine learning e come fallisce, inteso come una provocazione sia per l’informatica che per le discipline umanistiche, un modo per generare il dibattito sulle mistificazioni dell’intelligenza artificiale.
Nooscope, shows how Machine Learning works and how it fails
Esempio di traduzione sbagliata da Google Translate, la versione corretta è: Machine translation: advantages and limitations.
In un mondo sempre più globalizzato e interconnesso, servizi come Google Traduttore vengono usati per tradurre all’istante parole, frasi e pagine web tra l’italiano e più di 100 altre lingue. Le traduzioni automatiche sono affidabili ? Sono una minaccia per i traduttori professionisti? Quali sono i vantaggi e i limiti?
Le risposte a queste domande vengono dalla tesi di laurea “I sistemi di traduzione automatica: vantaggi e limiti” discussa dalla dott.ssa Erica Biotti, laureata in Lingue e Culture Moderne all’Università di Pavia, correlatore Roberto Marmo. Il suo profilo Linkedin evidenzia una grande passione per le lingue e le culture straniere, molto interessata anche al mondo digital, del web e del marketing, bene intenzionata al formarsi maggiormente in questi ambiti, in modo da ampliare sempre di più le sue conoscenze in prospettiva lavorativa. Pertanto, ha deciso di scrivere una tesi in cui unire le nuove tecnologie e la traduzione. Per informazioni e contatti scrivere alla sua email erica.biotti01@gmail.com
Come funzionano i software di traduzione automatica
Sono tre le diverse categorie secondo cui possono essere classificati. Negli anni ’50 furono creati i primi sistemi ditraduzione automatica basati su regole, utilizzano una combinazione di regole linguistiche e grammaticali, oltre a dizionari di parole comuni. Negli anni ’90 è introdotto un approccio più innovativo, basato sui sistemi di traduzione automatica basati su metodi statistici, che consistono semplicemente in una ricombinazione di traduzioni già esistenti ed effettuate da traduttori competenti.
Un importante passo in avanti è stato realizzato nel 2016, quando Google ha annunciato il rilascio di un sistema ditraduzione automatica basato su reti neurali, una svolta legata a recenti successi nel campo dell’intelligenza artificiale. L’aspetto più tipico di una rete neurale è la capacità di acquisire esperienza e di imparare dai propri errori. Questo sistema riesce infatti a perfezionarsi continuamente attraverso un’intelligenza basata su capacità di autoapprendimento (machine learning). Grazie alle reti neurali, Google ha migliorato notevolmente la qualità delle sue traduzioni.
Confronto fra l’accuratezza delle traduzioni realizzate con il sistema phrase-based (in azzurro), quelle realizzate dai sistemi neurali (in verde) e quelle redatte dai traduttori umani (in arancione). ( https://ai.googleblog.com/ 2016/09/a-neural-network-for-machine.html ).
Quali sono i vantaggi della traduzione automatica?
La traduzione automatica presenta dei vantaggi significativi: elevata velocità di esecuzione, sono disponibili gratuitamente, senza limitazioni per tutti gli utenti, vantaggi economici in termini di tempo risparmiato e di produttività, l’ampia gamma di lingue offerte, Google Translate supporta oltre 100 lingue a vari livelli.
La traduzione assistita come ausilio traduttivo
Le potenzialità del computer possono infatti rappresentare un utile ed efficace sostegno per il traduttore umano. Sull’integrazione fra competenze umane ed informatiche si basa il concetto di traduzione assistita, la quale permette al traduttore di incrementare la produttività tramite due funzionalità molto specifiche: la memoria di traduzione e il database terminologico.
La traduzione assistita si rivela utile soprattutto per testi di carattere tecnico-scientifico o normativo, dotati di una terminologia specifica, mentre trova dei limiti nei testi in cui è necessario preservare un certo grado di creatività, come ad esempio nella traduzione letteraria o audiovisiva, ovvero in tutti quei testi in cui la componente umana non può essere messa da parte.
Traduzione umana vs traduzione automatica
Consideriamo un esempio tratto dal film Erin Brockovich, un film estremamente interessante dal punto di vista traduttivo, caratterizzato da un linguaggio colloquiale, ricco di espressioni in slang, frasi idiomatiche e proverbi tipici dell’American English.
Ecco come si comporta Google Translate di fronte a queste varietà linguistiche:
Schermata della traduzione automatica di Google Translate con alcuni errori.
Come possiamo osservare, Google Translate presenta ancora dei problemi nella traduzione di espressioni fisse, come ad esempio le frasi idiomatiche, le quali non permettono una traduzione letterale in quanto il loro significato non è la somma dei significati delle parole che le compongono.
Questo è esattamente il lavoro del software di traduzione automatica: tradurre l’espressione idiomatica in modo letterale, dando luogo così a traduzioni assurde.
Questa è la traduzione italiana ufficiale del film, in cui notare un lavoro di adattamento al contesto e alla cultura di arrivo, fondamentale per la riuscita di una buona traduzione:
Ed
“Well, we’ll let the cat out of the bag… Tell the people the water’s not perfect. And, if we can ride out the year with no one suing, we’ll be in the clear forever.”
“Beh, noi vuotiamo il sacco, diciamo a tutti che l’acqua non è perfetta, e se la scampiamo per un anno senza che ci facciano causa siamo a posto per sempre.”
Come si può notare da questo esempio, le espressioni idiomatiche richiedono delle particolari strategie traduttive, essendo profondamente legate alla cultura e al contesto della lingua di partenza.
Spesso i sistemi di traduzione automatica non sono in grado di disambiguare espressioni che per il traduttore professionista, dopo aver analizzato il contesto, ma anche basandosi sul senso comune e sulla propria conoscenza del mondo, sono di immediata comprensione.
Traduzione delle sigle
Proviamo a fare qualche
prova con la traduzione delle sigle, molto spesso presenti nei testi. La frase
a sinistra è in lingua italiana, quella a destra è la versione tradotta da
Google:
1) tavolo
+ABC colore ROSSO = RED table + ABC
2) tavolo
+ABC colore ROSSO = table + ABC color RED
3)tavolo ABC colore ROSSO = ABC table color RED
4) tavolo
ABC colore ROSSO = ABC table color RED
5) tavolo
ABC+ colore ROSSO = ABC table + RED color
Come si può notare, sembra che nella
traduzione di Google il simbolo + venga compreso dal sistema di traduzione
automatica come un metodo per separare i vari termini.
Nel caso (2) il termine “table” viene
separato da “ABC” e “color RED”, non modificando la struttura iniziale; i casi (3)
e (4), non avendo il simbolo +, vengono interpretati da Google come un’unica
frase e quindi sia “ABC” che “colore rosso” sono entrambi considerati aggettivi
del sostantivo tavolo.
Nel caso (5) essendoci il simbolo +,
“tavolo ABC” e “colore ROSSO” sono considerate due frasi fra loro indipendenti.
“ABC” si riferisce soltanto al termine tavolo (e quindi nella traduzione viene
anteposto, in quanto aggettivo, al termine inglese “table”), mentre red viene
attribuito soltanto al sostantivo color.
Il caso più strano fra tutti sembra
essere il primo, poiché non segue lo schema dei casi precedenti, pur separando
i termini tramite il simbolo +. Nel primo caso viene eliminato il sostantivo
“colore” e nella traduzione l’aggettivo RED viene attribuito a table, mentre
ABC viene isolato dal simbolo +.
Viene da pensare è che Google Translate
fatichi a tradurre frasi contenenti degli errori (in questo caso è messo in
difficoltà dalla presenza del simbolo + e dalla parola ROSSO scritta in
maiuscolo). La traduzione automatica cerca di spezzare il testo in frammenti
minori, non è detto che corrispondano a singoli fonemi della lingua, per cui
può dar luogo a traduzioni assurde.
Possiamo concludere che il software di traduzione automatica, nel caso di espressioni fisse o espressioni profondamente connotate culturalmente, non eguaglia il lavoro del traduttore umano.
L’obiettivo della traduzione automatica non è ancora quello di garantire traduzioni perfette, bensì quello di produrre degli output fruibili seppur imprecisi. Nonostante i limiti che sono stati riscontrati, questi sistemi rappresentano comunque uno strumento molto utile attraverso il quale poter abbattere le barriere linguistiche. È molto probabile che i sistemi di traduzione automatica migliorino nel tempo; tuttavia, per il momento, possiamo affermare che l’essere umano rimane indispensabile nel processo traduttivo.
Sul canale YouTube denominato “Spot Promo prodotti con intelligenza artificiale” è disponibile una raccolta di video pubblicitari in cui viene citata l’intelligenza artificiale come caratteristica innovativa del prodotto. Molto utili per chi cerca idee sulla creazione di spot, o vuole analizzare come viene comunicata l’intelligenza artificiale. Ecco alcuni esempi.
Huawei Mate10 Pro intelligenza artificiale spot 2017
Nuova Mercedes Classe A, la rivoluzione dell’intelligenza artificiale
Fiat 500X – Traffic Sign Recognition e Speed Advisor – Riconoscimento segnali stradali
Eduardo Renato Caianiello è stato il primo studioso di neural network e cibernetica che ho conosciuto, mi iscrissi all’Università di Salerno anche perché ne era un prestigioso docente. Fonte di ispirazione per il suo lavoro accademico e per le ricadute delle sue attività nel territorio, quindi mi sembra giusto inaugurare questo blog con un breve racconto del suo percorso scientifico.
Eduardo Renato Caianiello (Napoli, 25 giugno 1921 – Napoli, 22 ottobre 1993) è stato un fisico italiano che ha introdotto nuove idee matematiche nella teoria quantistica dei campi e della rinormalizzazione. I suoi principali contributi hanno riguardato la Teoria Quantistica dei Campi e la Cibernetica, in particolare le Reti Neurali Adattative. Ha dato contributi importanti agli studi sulla possibilità di costruire modelli del cervello, come l’articolo “Outline of a theory of thought-processes and thinking machines” pubblicato nel Journal of Theoretical Biology volume 1, numero 2, aprile 1961, pag. 204-235.
In questo prestigioso articolo viene presentata la sua equazione che formalizza la teoria dell’apprendimento, il suo modello matematico di attività nervose è alla base degli attuali studi sui computer paralleli. Nell’articolo era sottesa la convinzione che il cervello umano, sebbene di tremenda complessità, obbedisse a leggi dinamiche non necessariamente complicate se si osserva l’operare dei singoli neuroni; e che tali leggi generassero in grandi assembramenti cellulari modi collettivi di comportamento, ai quali risultavano correlati i processi di pensiero.
L’incontro di Caianiello con la cibernetica e i suoi rapporti con Norbert Wiener, padre riconosciuto della cibernetica come studio unitario dei processi riguardanti la comunicazione e il controllo nell’animale e nella macchina, sono dettagliati nell’articolo “Quando Wiener era di casa a Napoli” scritto da Leone Montagnini.
Caianiello definì la teoria dell’informazione come il nucleo matematico della cibernetica, descritta come campo vastissimo, nonché tentativo di sintesi e ponte gettato tra molti rami del sapere.
Ernesto Burattini ha lavorato fianco a fianco con Eduardo Caianiello e racconta così su Avvenire.it la nascita della cibernetica napoletana: «Era l’anno 1954 e due signori, a bordo del tram “circolare rossa” di Roma, di ritorno da un seminario organizzato da Fermi sulla Teoria dell’Informazione e la Cibernetica di Wiener, incominciarono a discutere del sistema nervoso centrale e della possibilità di realizzarne un modello matematico» .
Nel 1968 nasce il Laboratorio di Cibernetica, dove lavorano fisici, matematici, biologi e informatici, impegnati a esplorare la neuroanatomia della corteccia cerebrale e i modelli matematici in grado di riprodurre i meccanismi di funzionamento del cervello. Il Laboratorio divenne l’Istituto di Cibernetica “Eduardo Caianiello” (Icib), con sede a Pozzuoli (Na).
Recentemente, è stato ridefinito come “Istituto scienze applicate e sistemi intelligenti (Isasi-Cnr)“, con l’ambizione di sviluppare e mettere in pratica un ambiente cooperativo forte in grado di sostenere l’eccellenza attraverso un arricchimento reciproco tra diverse discipline come le scienze fisiche, scienze della vita, ingegneria e l’intelligenza artificiale nel moderno scenario della “convergenza delle scienze” che va oltre i confini delle singole discipline.
Una lettura consigliata è il suo libro “Divagazioni sulla scienza e sul mondo“ dell’editore Liguori nel 1996, una raccolta postuma di suoi scritti di carattere divulgativo/storico/filosofico dal 1977 al 1993.
Nell’immagine seguente il suo autografo insieme a quello del fisico, divulgatore scientifico e accademico Antonino Zichichi, in occasione di una loro lezione a Salerno sulla cibernetica, che ricordo sempre con grande emozione.
Autografi di due prestigiosi studiosi, Antonino Zichichi ed Eduardo Caianiello.
Utilizziamo i cookie per essere sicuri che tu possa avere la migliore esperienza sul nostro sito. Se continui ad utilizzare questo sito noi assumiamo che tu ne sia felice.Ok